Zero-shot Music Editing
with Disentangled Inversion Control
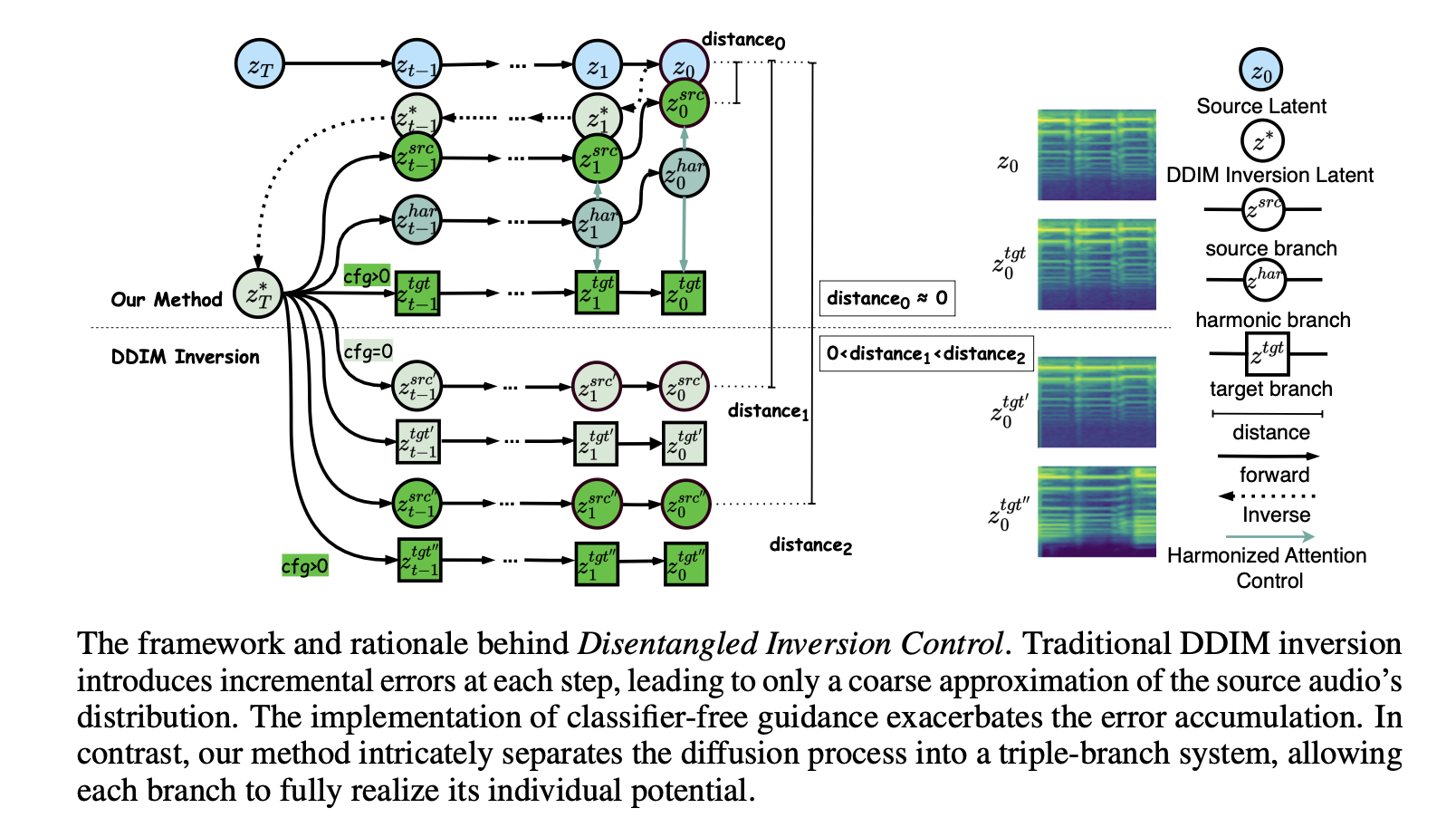
Text-guided diffusion models catalyze a paradigm shift in audio generation, facilitating the adaptability of source audio to conform to specific textual prompts. Recent advancements introduce inversion techniques, like DDIM inversion, to zero-shot editing, exploiting pre-trained diffusion models for audio modification. Nonetheless, our investigation exposes that DDIM inversion suffers from an accumulation of errors across each diffusion step, undermining its efficacy. And the lack of attention control hinders the fine-grained manipulations of music. To counteract these limitations, we introduce the Disentangled Inversion technique, which is designed to disentangle the diffusion process into triple branches, thereby magnifying their individual capabilities for both precise editing and preservation. Furthermore, we propose the Harmonized Attention Control framework, which unifies the mutual self-attention and self-attention with an additional Harmonic Branch to achieve the desired composition and structural information in the target music. Collectively, these innovations comprise the Disentangled Inversion Control (DIC) framework, enabling accurate music editing whilst safeguarding structural integrity. To benchmark audio editing efficacy, we introduce ZoME-Bench, a comprehensive music editing benchmark hosting 1,100 samples spread across 10 distinct editing categories. Our method demonstrates unparalleled performance in edit fidelity and crucial content preservation, outperforming contemporary state-of-the-art inversion techniques.